What we do
We develop amazing tools to help our users Search for, Extract and Normalize content from SEC EDGAR filings. We have a custom developed search engine with 9 search operators and more than 35 ways to filter documents. We offer extraction tools that help users extract search context and specific tables from those filings. We have normalization tools that help convert the stuff in EDGAR filings into data. In addition we extract and normalize a significant amount of data ourselves and make it available to our clients minutes after the original filings have been pushed to EDGAR. A partial list of the data we process includes Executive Compensation tables, Director Compensation Tables, Beneficial Ownership tables and the Tax Rate Reconciliation. Our tools are used by academic researchers to collect data not available from other sources to test new and complex hypotheses about factors influencing stock prices and corporate governance. Governance professionals use our tools to help them develop solid recommendations for their clients and corporate clients use our data to more quickly keep track of compensation changes happening with their competitors and peers.
directEDGAR
With more than 20 years of experience working with EDGAR filings our team has developed the most efficient, effective and easy-to-use tools to Search for, Extract & Normalize data from EDGAR filings. We understand that a deep-dive into EDGAR is not just about the search results. Once the search results have been identified the next step is converting those into content that can be used in meaningful ways. The directEDGAR Search, Extraction & Normalization Engine was developed to provide our clients with the tools they need to implement verifiable and accountable processes for not just finding data in EDGAR filings but making that data available to their empirical models. In addition we provide next day access to a host of content from EDGAR filings that has been Extracted and Normalized with value-added content.
Search

When considering a search tool the focus should be on granularity, finding the right documents. directEDGAR's Search, Extraction and Normalization Engine offers the most complete set of search features to help find the most relevant results. Our key search features include:
- Nine Boolean and positional search operators to help define the search
- More than 35 ways to filter search results including lists of CIK, report dates, conformed dates, 8-K filing reason codes . . .
Extraction

Identifying tens of thousands of documents with relevant content is not enough — our software provides a comprehensive suite of Extraction features to make it easy for our users to go from search results to data.
- Search Summary — One click access the details about every document as well as word counts and frequencies for all search terms
- Search Context — Our users can define the scope of context to be extracted directly to a CSV file
- Document Extraction — Our system lets users automatically pull the complete set of search result documents so they can be manipulated using text analytics and NLP processes
- Table Snipping — We offer the only Table Snipping processor in the market for when the relevant content is contained in a table.
Normalization
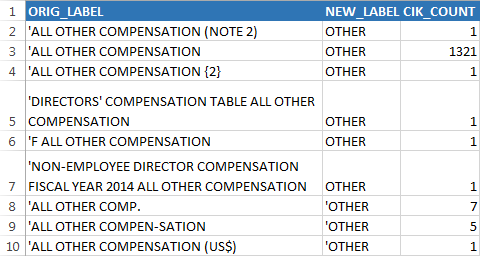
Normalization is the term we use to describe the process of unifying data in context or tables to a form that is ready for analysis. Our advanced Normalization features include
- Text Content Normalization Tools — identify numbers (expressed as digits or words) in extracted context and isolating it adjacent to the content
- Table Normalization Tools — support the entire process associated with extracting the rows, columns and data values from thousands of tables and unifying the output into one CSV file.
Pre-Processed Content
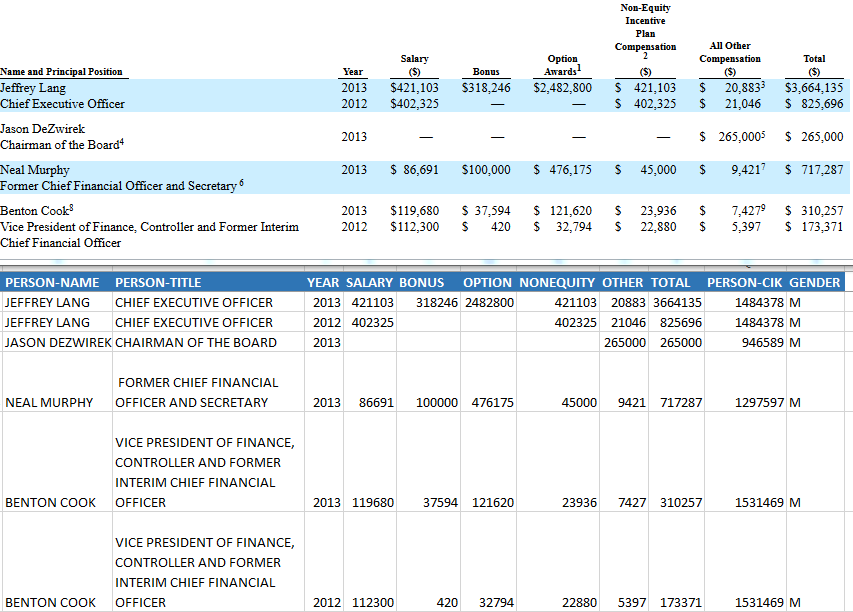
In 2014 we began pre-processing specific content from EDGAR filings. Our initial focus was on Executive Compensation tables but since then it has expanded to cover a broader range of content from the filings. This content is processed daily and pushed to our server for download � generally within 24 hours after the source filing has been made available on EDGAR. The content includes:
- Executive and Director Compensation Tables (with SEC assigned CIK identifiers for the individuals as well as their Gender as indicated in the source filings using Artificial Intelligence processes
- Audit Fee tables where we have recently begun standardizing the reported units across entities
- 10-K Item Number sections we parse 10-K filings to identify each section defined by Item Numbers and then push each separate section (Management's Discussion and Analysis, Risk Factors, Business . . .) so they can be downloaded by our clients for use in their analytical and Natural Language Processing models.
Overview
Successfully collecting data from SEC EDGAR filings requires much more than just finding some words in a collection of filings. While we often have some strict ideas about how the data should be present the filings are assembled by humans whose ideas might be different from ours. Our software reflects an overall strategy that collecting data requires the identification of relevant documents, extracting relevant content and then normalizing that content. This three minute video will give you a high level view of our Search, Extraction & Normalization Engine.
Citations
Our customers continue to do some amazing research using data they collected from EDGAR filings using one or more of the features in directEDGAR's Search, Extraction & Normalization Engine. Please look over this growing list.
| Author(s) | Title | Journal Details |
|---|---|---|
| Matthew Ege Jennifer L. Glenn John R. Robinson | Unexpected SEC Resource Constraints and Comment Letter Quality | Journal of Accounting Literature, In press, journal pre-proof, Available online 23 July 2019 |
| Phillip T. Lamoreaux, Lubomir P. Litov, Landon M. Mauler | Lead Independent Directors: Good Governance or Window Dressing? | Contemporary Accounting Research, Online Early Accessed Online 8/18/2019 |
| Brooke Beyer, Donald R. Herrmann and Eric T. Rapley | Disaggregated Capital Expenditures | Accounting Horizons, Online Early Accessed Online 8/18/2019 |
| Jacob Z. Haislip, Khondkar Karim, Karen Jingrong Lin and Robert Pinsker | The Influences of CEO IT Expertise and Board-Level Technology Committees on Form 8-K Disclosure Timeliness | Journal of Information Systems, Online Early Accessed Online 8/18/2019 |
| A. Erin Bass | Top Management Team Diversity, Equality, and Innovation: A Multilevel Investigation of the Health Care Industry | Journal of Leadership & Organizational Studies, Vol. 29, Issue 3. 3 (August 2019) pp. 339-351 |
| Alan I. Blankley, Philip Keejae Hong and Kristin Roland | Expected Benefit Payments and Asset Allocation in Defined Benefit Plans Post-SFAS 132(R) | Accounting Horizons, Sep 2018, Vol. 32, No. 3 (September 2018) pp. 71-82 |
| Rubeena Tashfeen and Tashfeen Mahmood Azhar | The proxies conundrum | Management Research Review, Volume 41, Issue 4, 2018, Pages 453-486 |
| Ulf Brüggemann, Aditya Kaul, Christian Leuz, and Ingrid M. Werner | The Twilight Zone: OTC Regulatory Regimes and Market Quality | The Review of Financial Studies, Volume 31, Issue 3, 1 March 2018, Pages 898–942 |
| Bryan Brockbank and Karen Hennes | Strategic Timing of 8-K Filings by Privately Owned Firms | Accounting Horizons, Online Early Accessed Online 2/24/2018 |
| Xiaoyan Cheng, David Smith and Paul Tanyi | An analysis of proxy statement leadership structure justification disclosures | Review of Quantitative Finance and Accounting, Accessed Online 2/9/2018 |
| Oded Rozenbaum | EBITDA and Managers’ Investment and Leverage Choices | Contemporary Accounting Research, Volume 36, Issue 1, Spring 2019, Pages 513-546 |
| Hans B. Christensen, , Eric Floyd, , Lisa Yao Liu, and Mark Maffett | The Real Effects of Mandated Information on Social Responsibility in Financial Reports: Evidence from Mine-Safety Records | Journal of Accounting and Economics, Volume 64, Issues 2–3, November 2017, Pages 284-304 |
| Marsha B. Keune, Timothy M. Keune, Linda A. Quick | Voluntary Changes in Accounting Principle: Literature Review, Descriptive Data, and Opportunities for Future Research | Journal of Accounting Literature, Volume 39, December 2017, Pages 52-81 |
| Manoj Kulchania and Shawn Thomas | Cash Reserves as a Hedge against Supply-Chain Risk | Journal of Financial and Quantitative Analysis, Available Online 9/11/2017 |
| Subramanian Rama Iyer and Ramesh P. Rao | Share Repurchases and the Flexibility Hypothesis | The Journal of Financial Research, Fall 2017, Vol. 40, Issue 3, pp 287 - 313 |
| Sophia J. W. Hamm, Boochun Jung and Woo-Jong Lee | Labor Unions and Income Smoothing | Contemporary Accounting Research, Volume 35, Issue 3, Fall 2018, Pages 1201-1228 |
| Hans B. Christensen and Valeri V. Nikolaev | Contracting on GAAP Changes: Large Sample Evidence | Journal of Accounting Research, Volume 55, Issue 5, December 2017, Pages: 1021–1050 |
| Yangyang Chen, Shibley Sadique, Bin Srinidhi and Madhu Veeraraghavan | Does High-Quality Auditing Mitigate or Encourage Private Information Collection? | Contemporary Accounting Research, Volume 34, Issue 3, Fall 2017, Pages: 1622–1648 |
| Andrew A. Acito, Chris E. Hogan, and Richard D. Mergenthaler | The Effects of PCAOB Inspections on Auditor-Client Relationships | The Accounting Review, Mar 2018, Vol. 93, No. 2 (March 2018), Pages 1-35 |
| Marsha B. Keune and Timothy M. Keune | Do Managers Make Voluntary Accounting Changes in Response to a Material Weakness in Internal Control? | AUDITING: A Journal of Practice & Theory, May 2018, Vol. 37, No. 2, Pages 107-137 |
| Paul A. Griffin, David H. Lont & Estelle Y. Sun | The relevance to investors of greenhouse gas emission disclosures | Contemporary Accounting Research, Volume 34, Issue 2, Summer 2017, Pages: 1265–1297 |
| Sabrina Chi, Shawn X Huang & Juan Manuel Sanchez | CEO Inside Debt Incentives and Corporate Tax Sheltering | Journal of Accounting Research,September 2017, Volume 55, Issue 4 pp. 837 - 876 |
| Brooke Beyer, Jimmy Downes & Eric T. Rapley | Internal capital market inefficiencies, shareholder payout, and abnormal leverage | Journal of Corporate Finance, April 2017, Vol. 43, pp. 39–57 |
| Robert Prilmeier | Why Do Loans Contain Covenants? Evidence from Lending Relationships | Journal of Financial Economics, Volume 123, Issue 3, March 2017, Pages 558-579 |
| Joshua J. Filzena, Maria Gabriela Schutteb | Comovement, financial reporting complexity, and information markets: Evidence from the effect of changes in 10-Q lengths on internet search volumes and peer correlations | North American Journal of Economics and Finance, January 2017, Vol. 39, pp. 19–37 |
| Tiantian Gu | U.S. Multinationals and Cash Holdings | Journal of Financial Economics, August 2017, Volume 125, Issue 2, pp. 344 - 368 |
| Dimu Ehalaiyea, Mark Tippett and Tony van Zijl | The predictive value of bank fair values | Pacific-Basin Finance Journal, February 2017, Volume 41, pp. 111 - 127 |
| Marian W. Moszoro, Pablo T. Spiller and Sebastian Stolorz | Rigidity of Public Contracts | Journal of Empirical Legal Studies, September 2016, Vol. 13, Issue 3, pp. 396-427 |
| Anthony Holder, Khondkar Karim, Karen (Jingrong) Lin and Robert Pinsker | Do Material Weaknesses In Information Technology-Related Internal Controls Affect Firms' 8-K Filing Timeliness And Compliance? | International Journal Of Accounting Information Systems 2016, Vol 22 No. 1 pp. 26-43 |
| Paul A. Griffen and Estelle Y. Sun | Troublesome Tidings? Investor's Response to a Wells Notice | Accounting and Finance Research: February 2016, Vol. 5, No. 1 pp. 99-120 |
| Paul A. Griffen, Amy Myers Jaffe, David H. Lont and Rosa Dominquez-Faus | Science and the stock market: Investors' recognition of unburnable carbon | Energy Economics: December 2015, Vol. 52, pp. 1-12 |
| Joshua J. Filzen | The Information Content of Risk Factor Disclosures in Quarterly Reports | Accounting Horizons: December 2015, Vol. 29 Issue 4, pp. 887-916. |
| Kyle Peterson, Roy Schmardebeck and T. Jeffrey Wilks | The Earnings Quality and Information Processing Effects of Accounting Consistency | The Accounting Review: November 2015, Vol. 90, No. 6, pp. 2483-2514. |
| Paul N. Tanyi and David B. Smith | Busyness, Expertise, and Financial Reporting Quality of Audit Committee Chairs and Financial Experts | AUDITING: A Journal of Practice & Theory: May 2015, Vol. 34, No. 2, pp. 59-89. |
| John L. Campbell, James Hansen, Chad A. Simon and Jason L. Smith | Audit Committee Stock Options and Financial Reporting Quality after the Sarbanes-Oxley Act of 2002 | AUDITING: A Journal of Practice & Theory: May 2015, Vol. 34, No. 2, pp. 91-120. |
| Ted D. Englebrecht, Cathy Zishang Liu & Thomas J Phillips, Jr. | The Information Content of Preferability Letters | Journal of Accounting and Finance: May 2015, Vol. 15, No. 1, pp. 95-118. |
| Jonathan C. Lipson, Rachel Martin, Ella Mae Matsumura, Emre Unlu | The Pattern in Securitization and Executive Compensation: Evidence and Regulatory Implications | Stanford Journal of Law, Business and Finance: Spring 2015, Vol. 20:2 |
| John Ziyang Zhang | Asset Securitizations and Credit Default Swaps | Financial Markets, Institutions & Instruments: November 2014, Vol. 23, No, 4, pp. 211�243. |
| Iftekhar Hasan, Chun-Keung (Stan) Hoi, Qiang Wu, Hao Zhang | Beauty is in the eye of the beholder: The effect of corporate tax avoidance on the cost of bank loans | Journal of Financial Economics: July 2014, Vol. 113, pp. 109-130 |
| Paul A. Griffin, David H. Lont and Kate McClune | Insightful Insiders? Insider Trading and Stock Return around Debt Covenant Violation Disclosures | Abacus: A Journal of Accounting Finance and Business Studies: June 2014, Vol. 50, No. 2 pp. 117-145. |
| S. M. Khalid Nainar, Atul Rai and Semih Tartaroglu | Market Reactions to Wells Notice: An Empirical Analysis | International Journal of Disclosure and Governance: May 2014, Vol. 11, No. 2, pp. 177-193. |
| Michaele Morrow and Robert C. Ricketts | Financial Reporting versus Tax Incentives and Repatriation under the 2004 Tax Holiday | Journal of the American Taxation Association: Spring 2014, Vol. 36, No. 1, pp. 63-87. |
| Xiaoyan Cheng, Lei Gao, Janice E. Lawrence, and David B. Smith | SEC Division of Corporation Finance Monitoring and CEO Power. | AUDITING: A Journal of Practice & Theory: February 2014, Vol. 33, No. 1, pp. 29-56. |
| Jeffrey R. Cohen, Udi Hoitash, Ganesh Krishnamoorthy and Arnold M. Wright | The Effect of Audit Committee Industry Expertise on Monitoring the Financial Reporting Process. | The Accounting Review January 2014, Vol. 89, No. 1 pp. 243-273 |
| Eric J. Allen, Char R. Larson and Richard G. Sloan | Accrual Reversals, Earnings and Stock Returns | Journal of Accounting and Economics: Spring 2013, Vol. 56, No. 1, pp. 113-129. |
| Paul A. Griffin and Yuan Sun | Going green: Market reaction to CSRwire news releases | Journal of Accounting and Public Policy: March-April 2013 Vol. 32, Iss:2, pp. 93-113. |
| Paul A. Griffin , David H. Lont and Yuan Sun | Supply chain sustainability: evidence on conflict minerals | Pacific Accounting Review: Vol. 26 Iss: 1/2, pp. 28-53. |
| Jap Efendi, Rebecca Files, Bo Ouyang, and Edward P. Swanson | Executive Turnover Following Option Backdating Allegations | The Accounting Review: January 2013, Vol. 88, No. 1, pp. 75-105. |
| Carolyn M. Callahan and Angela Wheeler Spencer | Risk Implications of Increased Off-Balance Sheet Disclosure: The Case of FIN 46 and SOX | Accounting and Finance Research: 2012, Vol. 1, No. 2, pp. 109-125. |
| Carolyn M. Callahan, Rodney E Smith and Angela Wheeler Spencer | An Examination of the Cost of Capital Implications of FIN 46 | The Accounting Review: July 2012, Vol. 87, No. 4, pp. 1105-1134. |
| Paul A. Griffin, David H. Lont, and Benjamin Segal | Enforcement and disclosure under regulation fair disclosure: an empirical analysis | Accounting & Finance: December 2011, Vol. 51, No. 4, pp 947-983. |
| Jonathan L. Rogers, Andrew Van Buskirk, and Sarah L. C. Zechman | Disclosure Tone and Shareholder Litigation | The Accounting Review: November 2011, Vol. 86, No. 6, pp. 2155-2183. |
| Ferdinand A. Gul, Bin Srindhi and Anthony C. Ng | Does Board Gender Diversity Improve the Informativeness of Stock Prices | Journal of Accounting and Economics: April 2011, Vol. 51, No. 3, pp. 314-338. |
| William Moser, Kaye Newberry, Andrew Puckett | Bank debt covenants and firms� responses to FAS 150 liability recognition: evidence from trust preferred stock | Review of Accounting Studies: 2011, Vol. 16, No. 2, pp. 355-376. |
| Paul A. Griffin and David H. Lont | Do Investors Care about Auditor Dismissals and Resignations? What Drives the Response? | AUDITING: A Journal of Practice & Theory: November 2010, Vol. 29, No. 2, pp. 189-214 |
| Hsihui Chang; Cheng, C. S. Agnes; Reichelt, Kenneth J. | Market Reaction to Auditor Switching from Big 4 to Third-Tier Small Accounting Firms. | AUDITING: A Journal of Practice & Theory: November 2010, Vol. 29, No. 2, pp. 83-114 |
A Partial List of our Clients





























Our History of Innovations
directEDGAR started as directSEARCH. Our roots go back to 1996 when Burch Kealey was a PhD student at the University of Oklahoma. He needed to collect the details of acquisitions made by public companies. This was a harsh introduction to the realities of data collection from SEC filings. When EDGAR came into existence and commercial vendors started selling search tools for EDGAR he got really excited until he realized that there was a pretty significant problem with existing search tools. They were amazing for finding all instances of certain words or phrase or they would quickly help you identify all instances of words or phrases in the filings of one company but none of them would allow you to easily run a search over a specific subset of companies that might number in the hundreds or thousands. Thus the first innovation we brought to the market was the ability to filter a search on a specific subset of companies using their CIKs. This brought our first customers who have continued to challenge us with their observations about how their research would be improved if only they could do this. The timeline below describes each of the innovations we have brought to collecting data from EDGAR filings and gives credit to those amazing researchers who wondered if directEDGAR could do this.
-
Collecting data from the Bizzell Library
1996Months and months spent scanning microfiche 10-K filings to find the amount of the purchase price allocated to goodwill for a large sample of acquiring firms.
-
Restatement data
2001Susan Shulz and Zoe Vanna Palmrose collected a comprehensive data set of firms involved in restatements. Burch was at a Kansas State Research Collequium where many other researchers were talking about that amazing data set and how challenging it must have been to collect that data. As Burch was driving back to Omaha after the meeting he was reflecting on his own past experiences hand collecting data and wondering how much research was trapped in the morass of hand collection of data from EDGAR filings.
-
Proof of concept
2005Burch had been mulling these issues over for some time and in 2004 the SEC released the regulations required by Sarbanes-Oxley. The business press was full of speculation about how these new regulations would impact audit fees. So Burch decided that it would be really cool to develop something to be able to capture and report on audit fees in a timely manner. The deadline for reporting 2004 audit fees for 12/31 firms was in early May of 2005 so Burch and his colleague Dr. Susan Eldridge decided to try to be first out the gate with some descriptive research on the impact of SOX on audit fees of 12/31 public companies in the Fortune 1000. While they did not have a fully functioning version of anything they had a number of pieces that made it possible to help them focus on their data collection. The initial data for the paper was fully collected about 12 hours after the last company in their sample filed their proxy on EDGAR. This provided some proof that the ideas that Burch had been mulling over could simplify the process of collecting raw data from EDGAR filings.
-
Launch
2007We initially started out with the name directSEARCH (you could directly search EDGAR filings) but that name was copyrighted by an employment agency so we had to change the name. However, we launched with the first, and we think still the easiest, way to search a set of EDGAR filings and limit the search result to a specific set of CIKs. It does not matter if you have 100 or 10,000 unique CIKs, our application allows you to either select a file with the list of CIKs or paste them into the list box. This is a critical feature when you need disclosures for only a subset of SEC registrants.
-
Table Snipping and SmartBrowser
2008Two of our earliest clients presented an interesting problem. They wanted to collect data from specific tables in 10-K filings. Ken Reichelt who was at Louisiana State University and Alan Blankley who was at the University of North Carolina at Charlotte had a similar problem. Professor Reichelt wanted to collect data from the Selected Financial Data table (Item 6 in a 10-K) and Professor Blankley was trying to collect data from the Valuation and Qualifying Accounts table in the 10-K. They were using directEDGAR to search and identify the table but they had research assistants and they wanted to be able to pass the table to those research assistants so they could then transfer values from those tables to Excel files for use in their research. They both felt it would really make their lives easier if they could just pass the tables to their assistants instead of forcing them to learn how to use directEDGAR. These requests, coming so close to one another led to the development of the original TableSnipper. However, once tables were 'snipped' from the filings they were painful to look at because the users would have to go to the directory with the files and click on them one at a time. Once we understood how painful that was we developed the SmartBrowser which is an amazing tool as it sequentially loads all htm and txt files in a selected directory and then allows users to view them, delete them or transfer them to another directory if needed. All of this is accomplished by mouse-clicks instead of having to open and close files and do the other manual steps associated with file review.
-
Dehydration/Rehydration
2009Numerous clients using the TableSnipper were coming back to us and wondering why we could not just get the table data into a csv file. Their thoughts were that if 10-K Wizard would extract the table into an Excel file we should be able to do the same. The problem we saw was that there is not really any advantage to just transfer the data from individual tables into individual csv files. You still have to consolidate those tables for the data values to be useful. The problem with consolildation is that the registrants are using synonyms to describe the same underlying phenomena. Given that there is no way in advance to predict which tables a user might be trying to use to collect data we developed a two-step process for data consolidation. The first step was the dehydration step. Here all of the tables are scanned to identify the row labels and column headings. After deleting repeating values we present the users a csv file with the unique column headings and row labels. This allows our users the opportunity to consolidate the columns (or rows) by renaming the original values that are synonyms to some common value. The rehydration step then consolidates all of the data into one csv file without losing the identity of the source files. Early testers wondered if we could persist those associations they made and so this led to the development of user dictionary files so once a user maps Other Comp. into OTHER the system will automatically do the replacement in later uses of the dehydration step.
-
Text parsing Allen, Larsen & Sloan - Journal of Accounting and Economics Vol 56 (July 2013)
2010We were surveying the literature that has cited directEDGAR and came across this paper. The authors needed to collect data on inventory write-downs from 10-K filings. They described using directEDGAR to search for and filter on CIKs but then explained how they had to manually review each disclosure to identify the amount of the write-down. This caused us to wonder if we could improve this process. This led to the development of a text extraction and normalization feature. Users can specify a search phrase and then define the extraction of content (words or numbers) relative to the search phrase. Our application will then scan the search results and extract the defined words or numbers relative to the search phrase and place them in a separate column. This feature has turned out to be a real benefit to some of our clients. Tanyi and Smith's Auditing a Journal of Practice & Theory 2015 article 'Busyness, Expertise and Financial Reporting Quality of Audit Committee Chairs and Financial Experts' used this feature to extract and normalize the audit committee meeting frequency from a large collection of proxy and 10-K filings.
-
Word Counts & Frequencies
2012Our clients began expanding their data requirements from just numbers to data about the documents as more research became focused on sentiment and content analysis. We had been asked several times to help users get word counts and frequencies from various documents so we developed and added tools to our ExtractionEngine that would allow users to collect those attributes from any document collection from our archives.
-
Started the Use of an Amazon Server to Augment Our Feature Set
2014By 2014 we had our first Bootcamp and Burch had made over 50 visits to client schools. A consistent observation was that many people were doing many of the same tasks. Two tasks in particular seemed like areas we could help. First we found many of our clients were using directEDGAR to create richer compensation data sets than were available from other sources and then many others were trying to isolate particular sections of 10-K filings. Given that we see it our mission to help research we thought we should try to streamline that process. Thus we began extracting and normalizing Executive and Director compensation and writing routines to divide 10-K forms into their constituent Item-# sections. We needed a distribution method and discovered how we could load the content on an Amazon server and have users submit a request file to the server with the server returning either the 10-K sections or the compensation data.
-
Daily Automatation Processes & Adding CIKs and a Gender Identifier to Compensation Data
2015Once we started preprocessing some data in 2014 the next step had to be to automate these processes with the goal to make it possible to have all of the proxies and 10-Ks filed by 12/31 firms available to our clients no later than 5/1 - the day after the proxy filing deadline for 12/31 firms. We focused our development on converting many of our ExtractionEngine tools to forms that could be used in a machine controlled process. By May of 2015 we had made significant progress. We also introduced the matching of individual person CIKs to their names in the compensation tables to provide our users with a persistent identifier so they can more easily track excutives and directors across firms and time. Some of our clients had been also trying to identify the gender of executives and directors so we augmented our processes to identify their gender and add it to the compensation data.
-
Release of Search Extraction & Normalization Engine
Complete Reimagination of Software & Introduction of Custom Indexing
2016We needed to enhance our search features and modernize our architecture. Most of our users had switched to 64 bit computers but our applications were not designed to take advantage of the increased power. In particular, more and more clients wanted to be able to search larger collections of SEC EDGAR filings at one time. So we started from scratch by adopting new search technology from dtSearch and combining all of the features into one coherent application. One of the other drivers of this reset was the significant number of requests we had received over the years for custom indexes of more limited or specific sets of filings. In addition, many of our users who were downloading the Item-# sections of 10-K filings wanted the ability to use the other features of our software on those particular document collections. We introduced custom indexing so users can point our application at a relevant set of documents and then use the full range of features on that set of documents. Now a user can identify and extract specific tables from say the Risk Factors section or use our Text Normalization tools on just the MD&A.